
AGI یا نه؟ موفقیت OpenAI O3 با پرسشهای تازه همراه است!
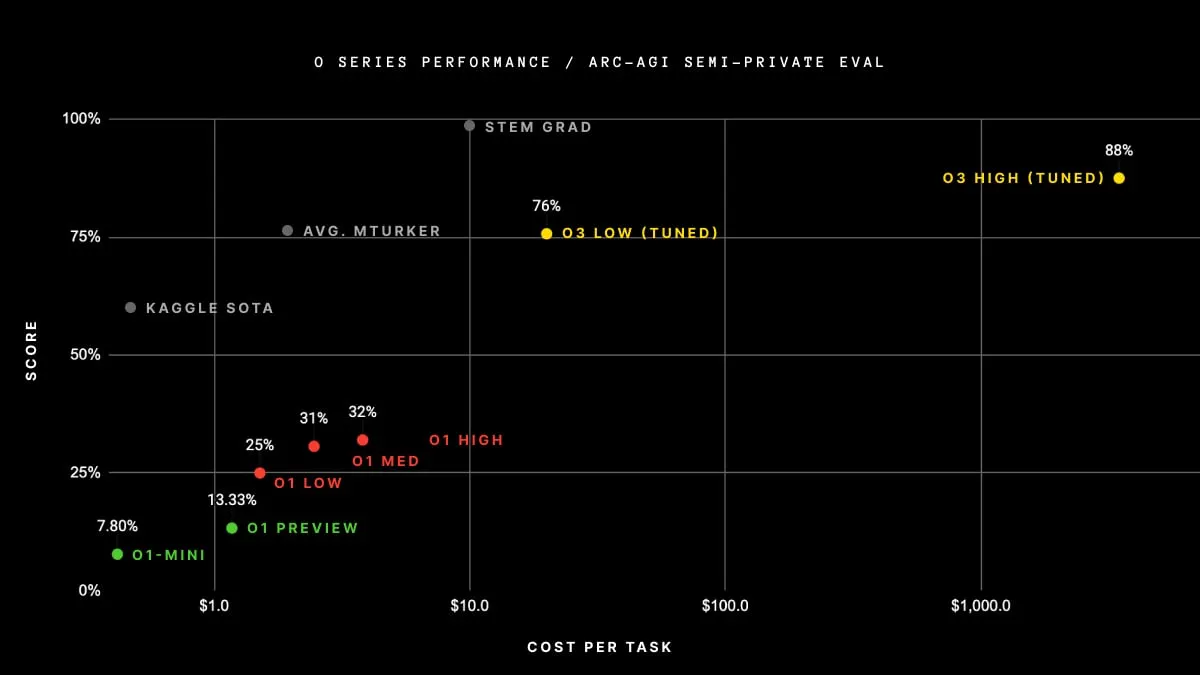
به گزارش زوم ارز، خانوادهی آخرین مدلهای هوش مصنوعی شرکت OpenAI، بهعنوان یک دستاورد قابل توجه، به موفقیتهایی دست یافتهاند که برای بسیاری از افراد غیرقابل تصور بوده است. با کسب امتیاز بیسابقهای به میزان ۸۷.۵ درصد در چالشهای پیچیده، این مدلها توانستهاند به حدی نزدیک به تواناییهای یادگیری خودی هوش عمومی مصنوعی برسند که قابلیت تلقین به انسان را در نظر گرفت.
معیار ARC-AGI به عنوان یک آزمون، ارزیابی میکند که یک مدل چه قدر به دستیابی به هوش عمومی مصنوعی نزدیک است. این به این معناست که آیا میتواند تفکر کند، مسائل را حل کند و در شرایط مختلف مانند یک انسان عمل کند، حتی در صورتی که بشر برای آن به آموزش ندهد. انجام این وظیفه برای انسانها نسبتاً آسان است، اما برای ماشینها، درک و حل آن چالشبرانگیز است.
یک شرکت تحقیقی در حوزه هوش مصنوعی که مقر آن در شهر سانفرانسیسکو قرار دارد، در هفته گذشته از محصولات o3 و o3-mini خود به عنوان بخشی از کمپین “۱۲ روز OpenAI” خود استفاده کرد. این اقدام تنها چند روز پس از معرفی گوگل از رقبای o1 خود را مشخص کرد. این انتشار نشان داد که شرکت OpenAI به دستیابی به هوش مصنوعی عام در آینده نزدیک بسیار نزدیک شده است.
| شاید دنبال کردن این اخبار برای شما مفید باشد: |
مدل جدید o3 برپایه استدلال OpenAI نشان میدهد که یک تحول اساسی در نگاه سیستمهای هوش مصنوعی به استدلالهای پیچیده رخ داده است. برخلاف مدلهای زبان بزرگ سنتی که بر تطابق الگو تمرکز دارند، o3 یک رویکرد جدید به نام “ترکیب برنامه” را معرفی کرده است که این امکان را فراهم میکند تا با چالشهای جدیدی که پیش از آن مواجه نشدهاند، روبهرو شوند.
تیم ARC در گزارش ارزیابی خود اظهار کرد که این تنها یک بهبود تدریجی نیست، بلکه یک پیشرفت واقعی است. در یک پست وبلاگ، فرانسوا شولت، یکی از بنیانگذاران جایزه ARC، حتی فراتر از این مفهوم رفته و توصیه کرده که “o3 سیستمی است که قادر به تطبیق با وظایفی است که تا کنون با آن مواجه نشده بودهایم، و احتمالاً به عملکرد سطح انسانی در حوزه ARC-AGI نزدیک میشود.”
تنها برای انجام مراجعه، اینجا اظهارات جایزه ARC را در خصوص نتایج امتحانات خود ذکر میکند: “میانگین عملکرد انسانی در آزمونها بین ۷۳.۳٪ تا ۷۷.۲٪ دقیق بود (میانگین مجموعه آموزش عمومی: ۷۶.۲٪؛ میانگین مجموعه ارزیابی عمومی: ۶۴.۲٪).”
با استفاده از تجهیزات محاسباتی پیشرفته، OpenAI به امتیاز ۸۸.۵% رسید. این علامت از مدل های هوش مصنوعی دیگری که در حال حاضر وجود دارند، برتری دارد.
AGI یا نه؟ موفقیت OpenAI O3 با پرسشهای تازه همراه است!
آیا o3 AGI AGI است؟ بعد از کسی بپرسید، باید مشخص باشد.
با وجود پیشرفت چشمگیر، هیئت مدیره جایزه ARC و سایر متخصصان تصریح کردند که هنوز AGI به دست نیامده است. بنابراین، جایزه ۱ میلیون دلاری هنوز برای دریافت باقی مانده است. اما، کارشناسان در صنعت هوش مصنوعی در نظرات خود در مورد اینکه آیا o3 معیار AGI را نقض کرده است یا خیر، یکتا نظری به ارمغان نیاوردند.
بعضی افراد، از جمله Chollet، با ایدهی اینکه آیا خودآزمون محک زدن بهترین معیار برای ارزیابی اینکه آیا یک مدل به حل مسائل واقعی و نزدیک به هوش انسانی میرسد یا نه، مشکل داشتند. Chollet اظهار کرد: “گذراندن ARC-AGI فقط به AGI نزدیکی را نشان نمیدهد و من فکر میکنم که o3 هنوز AGI نیست. O3 هنوز هم در برخی از وظایف بسیار ساده شکست میخورد، که نشان میدهد تفاوتهای اساسی آن با هوش انسانی هستند.”
او اشاره کرد به یک نسخه جدیدتر از معیار AGI که به نظر او یک معیار دقیقتر از نزدیک شدن هوش مصنوعی به توانایی استدلال مانند یک انسان را ارائه میدهد. Chollet بیان کرد که دادههای اولیه نشان میدهد معیار ARC-AGI-2 در آینده همچنان یک چالش بزرگ برای o3 ایجاد میکند و احتمالا حتی در محاسبات بالا ممکن است امتیاز آن به زیر ۳۰ درصد کاهش یابد (در حالیکه یک انسان باهوش هنوز میتواند امتیاز بالاتری به دست آورد، بدون نیاز به آموزش ۹۵ درصد).
دیگر مشکوکان حتی ادعا کردند که OpenAI با اثربخشی این آزمایش را انجام داده است. مدلهای مانند o3 از ترفندهای برنامهریزی بهره میبرند. آنها به منظور بهبود دقت مراحل را ترسیم میکنند اما هنوز نیز پیشگوییهای پیشرفتهای میباشند. به عنوان مثال، وقتی o3 “حروف را میشمارد”، یک متن درباره شمارش تولید میکند نه استدلال واقعی،” اظهارات لوون ترتریان، یکی از بنیانگذاران Zeroqode، در X بود.
دیدگاهی مشابه با سایر دانشمندان هوش مصنوعی از جمله محقق معروف و برنده جوایز هوش مصنوعی، ملانی میچل، وجود دارد. او به این نتیجه رسیده است که o3 واقعاً استدلال نمیکند، بلکه یک فعالیت «جستجوی اکتشافی» را انجام میدهد.
Chollet و سایر افراد اشاره کردند که OpenAI به نحوی کامل شفاف در مورد عملکرد مدلهای خود نبود. میچل اظهار کرد: به نظر میرسد که این مدلها به طریقی که ممکن است بسیار متمایز از روش جستجوی درخت مونت کارلو در الفازیرو باشد، بر روی فرآیندهای زنجیرهای فکری مختلف آموزش دیدهاند. به این معنا که آنها نمیدانند چگونه یک مشکل جدید را حل کنند، و به جای آن از مجموعه وسیعی از دانش خود برای اعمال ممکنترین زنجیره فکر به تاخیر بیافته تا زمانی که به یافتن راهحل شکستناپذیر برسند.
AGI یا نه؟ موفقیت OpenAI O3 با پرسشهای تازه همراه است!
به عبارت دیگر، o3 بسیار وابسته به یک کتابخانه گسترده برای آزمایش و خطا است و اصلاً خلاق نیست.
“قوای بی رحمانه هوش را برابر قرار نمیدهد. جف جویس، موجه پادکست Humanity Unchained، در پروفایل لینکدین خود ادعا میکند که o3 برای دستیابی به امتیاز غیررسمی خود، نیازمند قدرت محاسباتی قوی است. یک AGI واقعی باید به طور موثر مسائل را حل کند. حتی با منابع بینهایت، o3 نمیتواند بیش از ۱۰۰ معما که انسانها به سهولت آنها را حل میکنند، برطرف کند.”
وحیدی کاظمی، یک محقق از OpenAI، در کمپ “This is AGI” شرکت کرده است. او اظهار داشت: “به نظر من ما قبلاً به AGI دست یافتهایم”، با اشاره به مدل o1. وحیدی کاظمی استدلال کرد که این مدل نخستین مدلی بود که به جای پیشبینی نشانه بعدی، برای استدلال طراحی شد.
با استفاده از منهج علمی مشابه، او اظهار کرد که رد کردن مدلهای هوش مصنوعی غیر AGI به دلیل پیروی از دستورالعملهای از پیش تعیینشده، با علمی بر مبنای تکیه بر مراحل منظم و تکرارپذیر بیارتباط است. او تاکید کرد که به گفته OpenAI، هیچ انسانی هنوز در هیچ وظیفهای بهتر از این مدلها عمل نکرده است.
به نظر من، ما از پیش از AGI فراتر رفتهایم و O1 بهتر است. ما هنوز “بهتر از هیچ انسانی در هیچ کاری” نیستیم، اما در بیشتر زمینهها از بیشتر انسانها بهتر عمل میکنیم. برخی ادعا میکنند که LLM ها تنها میدانند چگونه دستورالعمل را اجرا کنند. بهطور اولیه، هیچ کس نمیتواند واقعاً توضیح دهد…
وحید کاظمی در تاریخ ۶ دسامبر ۲۰۲۴ بر روی توییتر نوشت.
به طور خصوصی، سام آلتمن، CEO OpenAI در مورد رسیدن به هوش مصنوعی کلی (AGI) یا عدم رسیدن به آن، اظهار نظری قطعی ندارد. او به سادگی اعلام کرد که “o3 یک مدل بسیار هوشمند است” و “o3 mini یک مدل بسیار هوشمند است، با امکانات و کیفیت واقعاً عالی، اما با هزینه و عملکرد قابل بهبود.”
منبع: decrypt.co











نظرات کاربران